
データセットのデータクリーニングができたらEZRで解析を行います。まずはデータセットの読み込みを行い、解析ができる状態にします。
EZRはWindows、Macでタブの位置が異なる場合があります。みんなの統計疫学教室ではWindowsを使用しています。
データクリーニングはこちら データクリーニング
データセットの読み込み
●ファイルの種類ごとに選択する方法
ファイル➡データのインポート
ファイルの種類ごとにSPSS、Minitab、Stata、Excelなどから選択します。
●コピー&ペーストでインポートする方法
うまくインポートできればよいのですが、全角が入っていたり、ファイル名と同じ変数名があったりすると読み込めない場合があります。そのときはExcelからコピー&ペーストで読み込みましょう。
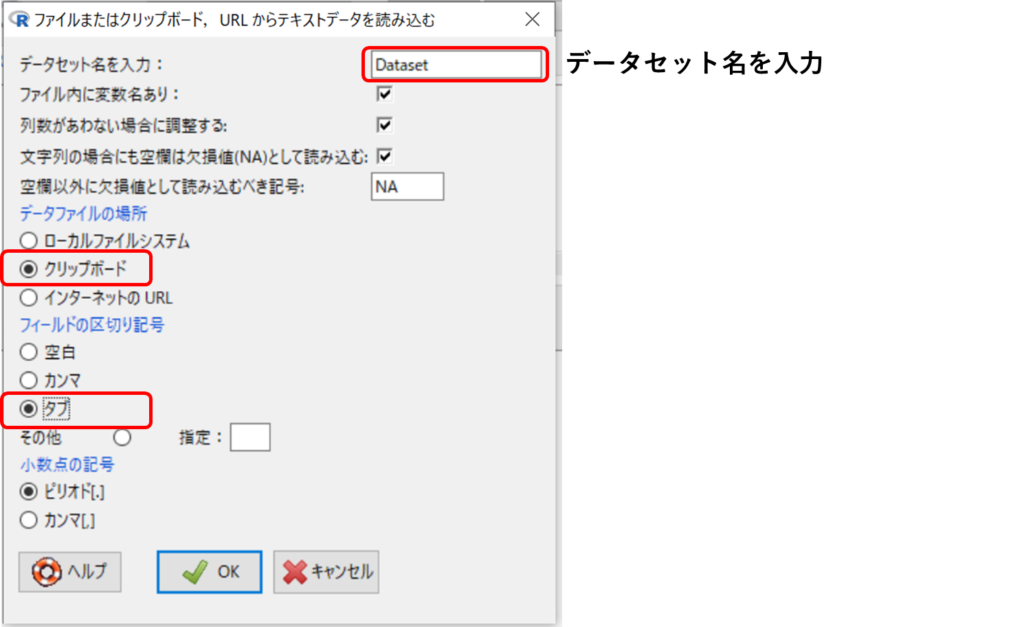
①ファイル➡データのインポート➡ファイルまたはクリップボード、URLからテキストデータを読み込む
②インポートしたいExcelの表を選択して、右クリックでコピー
③下図のようにデータセット名を入力し、[クリップボード]と[タブ]を選択し、[OK]
データの確認
アクティブデータセット➡変数の操作➡データセット内の変数を一覧する
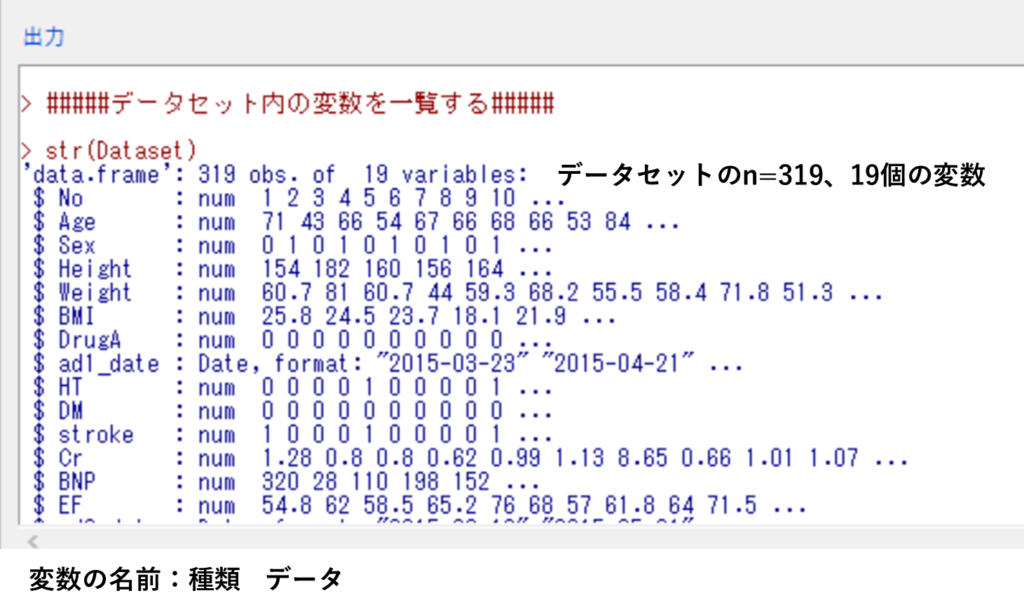
このように表示されます。
データや変数の個数、変数、変数の種類を確認します。
変数の種類は
・Int=整数(連続変数)
・Nun=実数(連続変数)
・Factor=因子(名義変数)
・Character=文字列
ここではSex(性別)は0=女性、1=男性の名義変数ですが、numとして表示されています。正確には名義変数でFactorですが、このままでも問題なく解析はできます。
Characterとなっている場合は解析ができないので、実数や因子に変換します。
アクティブデータセット➡変数の操作➡因子あるいは文字列として扱われている数値を連続変数に変換する または 全ての文字変数を因子に変換
必要な場合は連続変数をカテゴリー化する
年齢を60以上、以下に分けたサブグループ解析を行う場合、Hbの値を低値、正常値、高値の3群にわけて、正常値と比較して低値、高値の群で疾患のリスクが上昇するかみたい場合などは連続変数をカテゴリー化しておきます。
ここでは年齢を60歳未満、以上の2群に分けます。
アクティブデータセット➡変数の操作➡連続変数を指定した閾値で2群に分けた新しい変数を作成する(3群以上の場合は3群以上を選択)
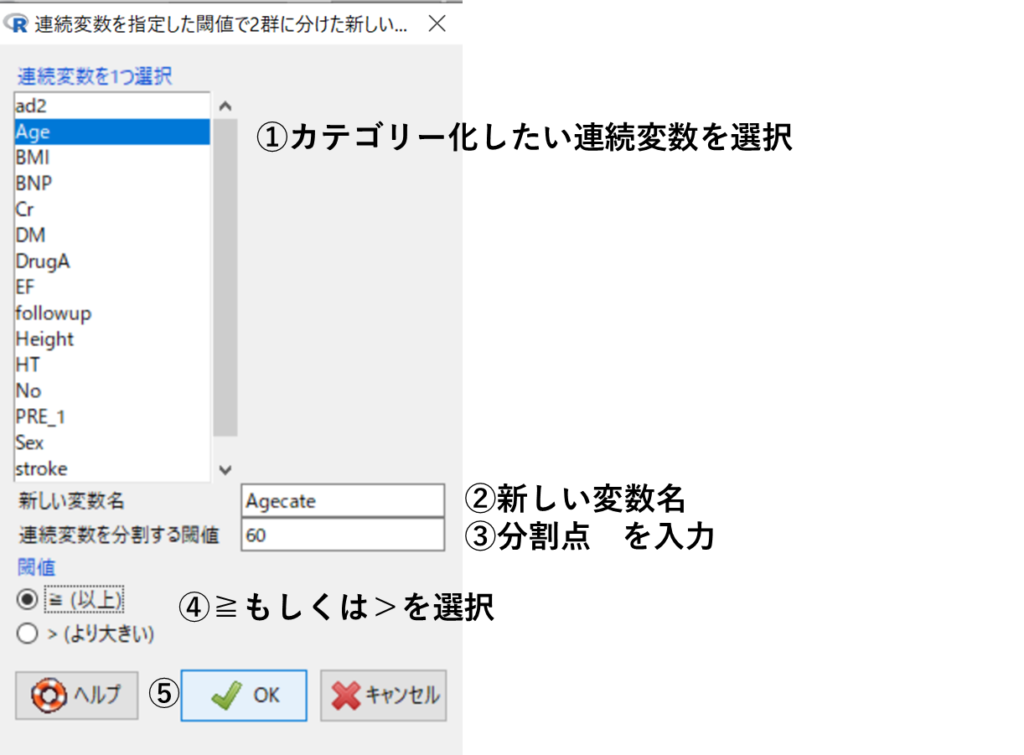
図2のように必要事項を入力してすると、図3のように出力されます。

60歳未満=0、60歳以上=1となっており、それぞれの個数も出力されています。
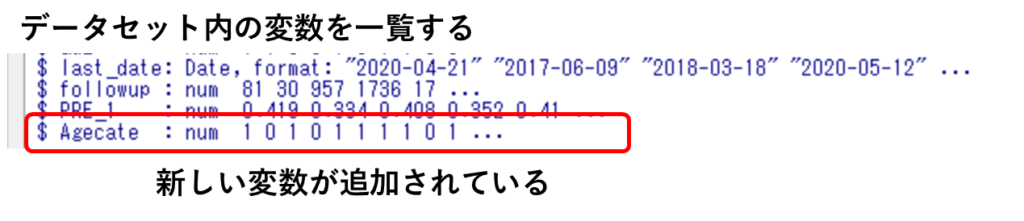
上記の方法でデータセット内の変数を一覧すると、新しく作成した“Agecate”が追加されています。
欠損値の確認
一般的には必要な項目に欠損値がある場合、そのデータは除外されて解析されます。複数の項目を必要とする多変量解析の場合は特にデータ数が大きく減ってしまうことになりかねません。欠損値がどの項目にどの程度あるのかを把握しておきましょう。
アクティブデータセット➡欠損値の操作➡指定した変数の欠損値を数える または 全ての変数の欠損値を数える
図5のように項目ごとに欠損値の数が出力されます。

準備ができたら解析を行いましょう!


コメント