
データ収集が終わったら、早く解析をして結果が知りたい!ということですぐに単変量解析にうつる方を多々見かけますが、まずは記述統計を行い、データセットはどのような特徴のある集団なのか、しっかり把握してから解析をスタートしましょう。
記述統計が重要な理由
理由は主に3つあります。
①自分の集めたデータがどのような特徴を持ったデータなのかを把握するため。
研究を報告するときに必ず「Patient characteristics」って報告しますよね。研究の結果を解釈するためにも、どのような患者群において行った研究なのかを理解しておくことが必要です。
②欠損値、誤入力がないかを確認するため。
③データの分布を確認することで、解析のときにどの検定を使うべきか明らかにするため。
それでは早速記述統計を行っていきましょう。連続変数と名義変数に分けて説明します。
連続変数の記述統計
Age(年齢)を例に記述統計を行います。
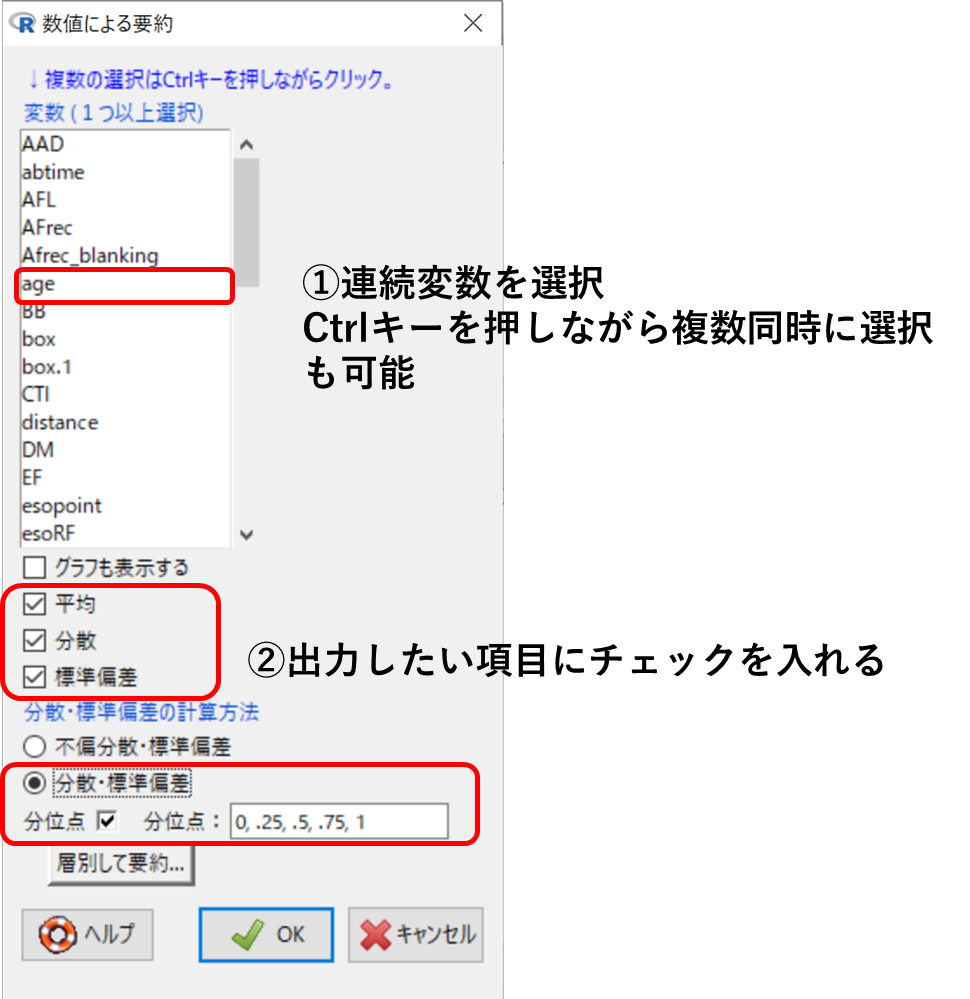
統計解析➡連続変数の解析➡連続変数の要約
対象となる連続変数を選択し、出力したい項目にチェックを入れます。
分散・標準偏差の計算方法に関しては、母集団全体の記述統計を行う場合には[分散・標準偏差]をチェックしておきましょう。

要約の記載に関しては正規分布に従うかどうかで記載方法が変わります。正規分布に従うかどうかの確認は別の項で説明しますので、ここでは割愛します。
正規分布に従う場合 平均±標準偏差 例:69.2±8.3
正規分布に従わない場合 中央値(25パーセンタイル―75パーセンタイル もしくは 四分位範囲) 例:71.0(63.7-77.0)もしくは71.0(16.3)
名義変数の記述統計
Sex(性別)を例に記述統計を行います。ここでは0=男性、1=女性としています。
統計解析➡名義変数の解析➡頻度分布
対象となる名義変数を選択し、図のようにチェックを入れます。
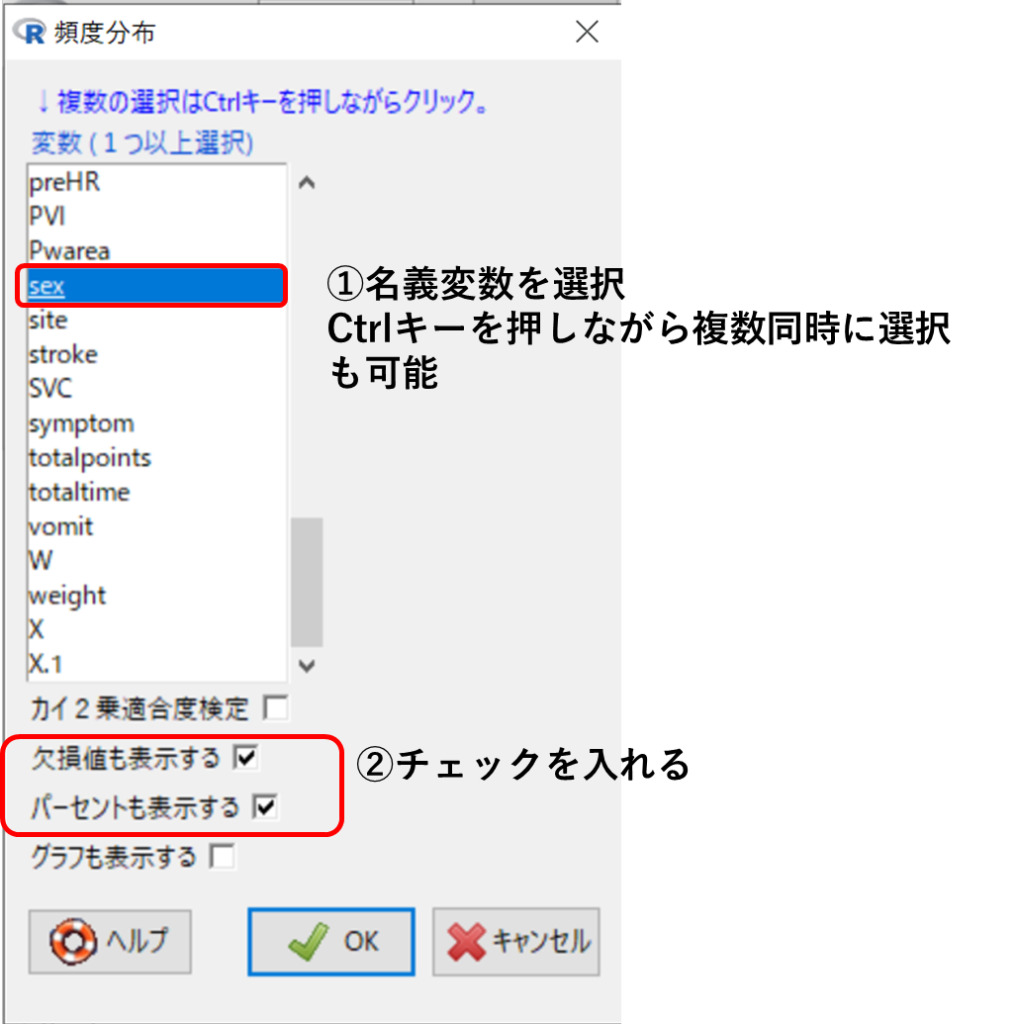

男性:9/20(45%)
ということがわかります。
記述統計の結果を表にまとめると、Patient characteristicsの表が完成します。
患者背景の把握ができたら、目的の解析に移りましょう。


コメント