
単変量解析が終わったら、多変量解析を行いましょう。
多変量解析のなかでもロジスティック回帰分析は臨床研究ではとても使いやすい分析方法です。条件は「従属変数が2値数であること」だけです。独立変数は名義変数でも、連続変数でも可能です。
参考までに、重回帰分析の場合は従属変数も独立変数も連続変数である必要があります。
検定方法の選択はこちら>>検定方法 いつ何を使う?
単変量解析はこちら>>Stataで単変量解析①-t検定とMann-Whitney検定, Stata単変量解析②-χ<sup>2</sup>(カイ二乗)検定とFisherの正確検定
※このページの見方
コマンドは・に続く部分です。
黒文字➡コマンド(定型)、青文字➡連続変数(continuous variable)、赤文字➡名義変数(categorical variable)
青文字や赤文字を変えて使いましょう。
独立変数の選び方

まずは独立変数の選び方です。一般的に臨床研究の場合はこのようなことが言われています。
一番上は少しわかりづらいかもしれませんが、例えば疾患発症の有無をアウトカムとしたとき、N=100の研究で発症が30人であった場合、30/7-10=3-4個の変数を入れてよいことになります。
医学研究の場合はどんな疾患も年齢と性別に影響を受けますので、年齢と性別を入れることはほぼ必須です。それを入れると残り入れられる変数は2つほどです。
Stataでロジスティック回帰分析
DrugAの使用が入院(ad2)を減らすか検定を行います。この場合は従属変数(Outcome)は入院、独立変数がDrugAとなります。共変量は年齢(Age), 性別(Sex), BMIを投入します。

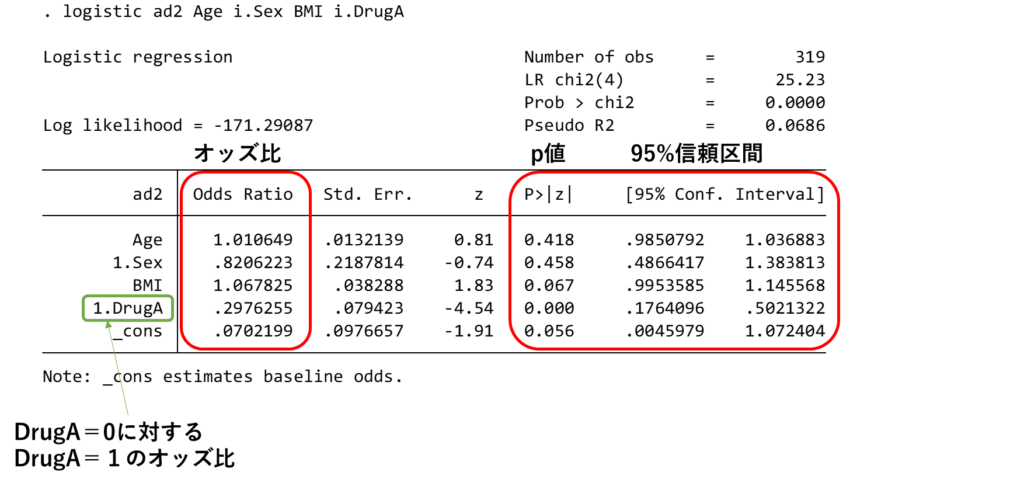
出力結果から読み取るとDrugA使用の入院に対するオッズ比(95%信頼区間)は0.30 (0.18-0.50), p<0.001となり、DrugAの使用は有意に入院を減らすと解釈できます。
モデルの当てはまりを確認
ロジスティック回帰分析モデルの当てはまりを確認するために、Hosmer-Lemeshow goodness-of-fitテストを行います。下記のコードを入力すると、直前に行ったロジスティック回帰分析のモデルを評価します。

p値が大きいほど、モデルの当てはまりがよいことを示します。


コメント