ランダム化比較試験が最もエビデンスレベルの高い研究ですが、臨床現場の状況、倫理的な面や費用などの面から行うことができない場合もあります。観察研究で患者背景をできるだけそろえることによって二つの治療方法の比較が行うことができないか、ということで行われるのが傾向スコア・マッチング propensity score matchingです。
傾向スコア・マッチングはロジスティック回帰分析が使用されることが多いので、今回は「治療Aと治療Bの5年生存(アウトカム)を比較するコホート研究」を例にしたいと思います。
マッチング
まず、マッチングについて説明します。性・年齢のマッチングは聞いたことがあるかもしれません。医学研究において性・年齢は交絡因子となるため、性・年齢の影響を除くために対象者の性・年齢を合わせます。
治療A群、治療B群からそれぞれペアを性・年齢が合うペアを探します。
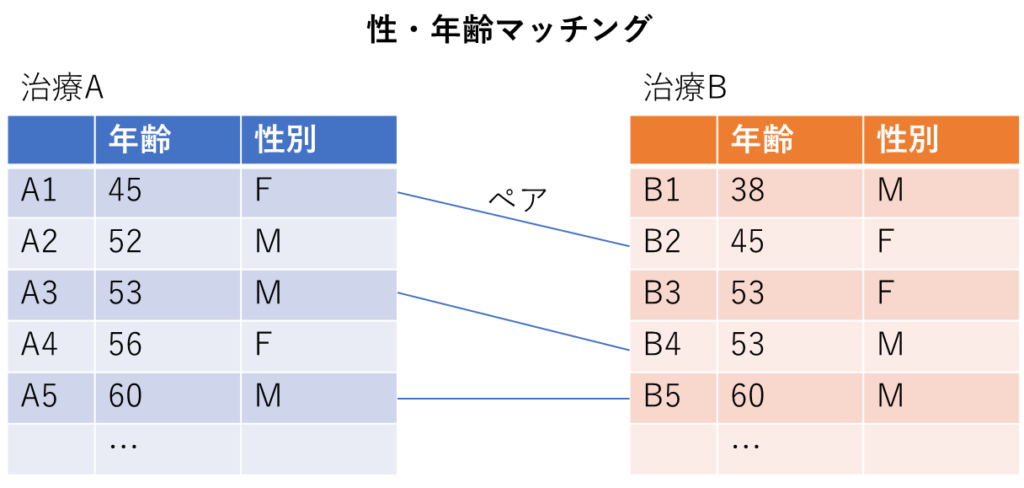
この例ではA1-B2, A3-B4, A5-B5という3ペアができました。こうすれば両群において年齢、男女比が同じになり、年齢と性別の影響を除くことができます。ペアができなかった人は解析に入れることができないので、対象者が少なくなってしまう点はデメリットです。
傾向スコア
性・年齢をそろえるだけならまだよいのですが、その他にも交絡因子となりえる基礎疾患や血液検査データ、病気の進行度などのデータもマッチングさせようとすると、ペアが見つからずに対象者がかなり少なくなってしまいます。
そこで使うのが傾向スコアです。A(もしくはB)の治療を受けやすい患者背景をスコア化してスコアをそろえます。傾向スコアは治療方法(A=1, B=0)を従属変数、患者背景因子を独立変数として、ロジスティック回帰分析を行い、算出します。傾向スコアには性別、年齢、基礎疾患、血液検査データ、病気の進行度など交絡因子になる患者背景を入れます。スコアは0~1で算出され、0は術式Bを1は術式Aを受けやすい患者背景となります。
傾向スコア・マッチング
算出した傾向スコアでマッチングを行っていきます。「最近傍マッチング」といって、傾向スコアの差が設定した範囲に収まっている2人をペアにする(スコアが全く一緒でなくても近ければペアにできる)という方法があります。
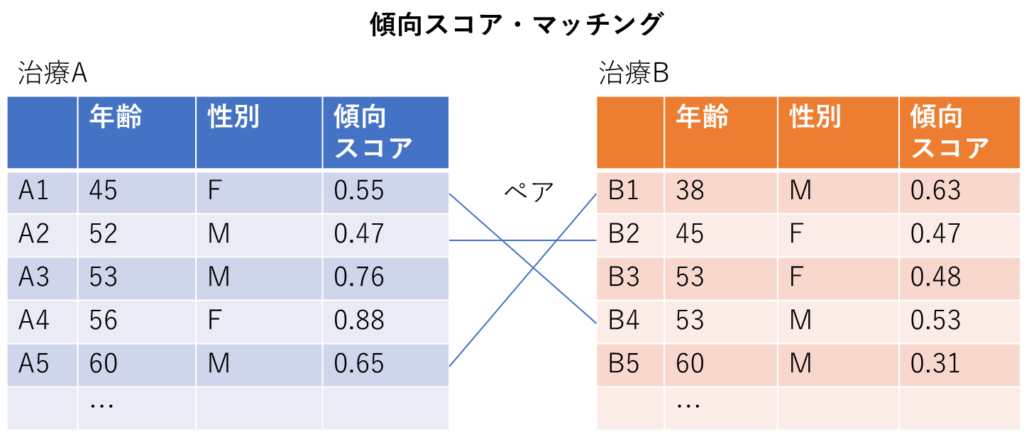
例ではA1-B4, A2-B2, A5-B1という3ペアができました。通常のマッチングのときと同様、ペアができなかった人は解析に入れることができません。
解析対象者が決まったら、従属変数(アウトカム)を5年生存、独立変数に傾向スコア、治療方法を入れてロジスティック回帰分析を行います。
傾向スコア・マッチングの注意点 未測定交絡
観察研究で2つの治療方法を比べることができるのであれば、わざわざランダム化比較試験を行わなくてもいいのでは?という声も聞こえてきそうですが、そんなことはありません。
傾向スコア分析の弱点は未測定交絡因子を制御できないという点です。例えば、手術の成績と術前のADLは大きく関連があると思われますが、ADLに関するデータがなければ、マッチングによっても背景をそろえることはできません。その限界を理解した上で、研究を行うことが重要です。


コメント