やっとデータ収集ができました!早く結果が知りたい!という気持ちはわかりますが、急がば回れ。その前に記述統計を行いましょう。
記述統計はどうして必要なのでしょうか?
記述統計が重要な理由
理由は主に3つあります。
①自分の集めたデータがどのような特徴を持ったデータなのかを把握するため。
研究を報告するときに必ず「Patient characteristics」って報告しますよね。研究の結果を解釈するためにも、どのような患者群において行った研究なのかを理解しておくことが必要です。
②欠損値、誤入力がないかを確認するため。
③データの分布を確認することで、解析のときにどの検定を使うべきか明らかにするため。
それでは早速記述統計を行っていきましょう。連続変数と名義変数に分けて説明します。
連続変数の記述統計①
エクセルデータをSPSSにインポートしたら、早速分析を開始します。
データのインポートはこちら>>SPSSを始めよう!データの挿入
分析➡記述統計➡度数分布表
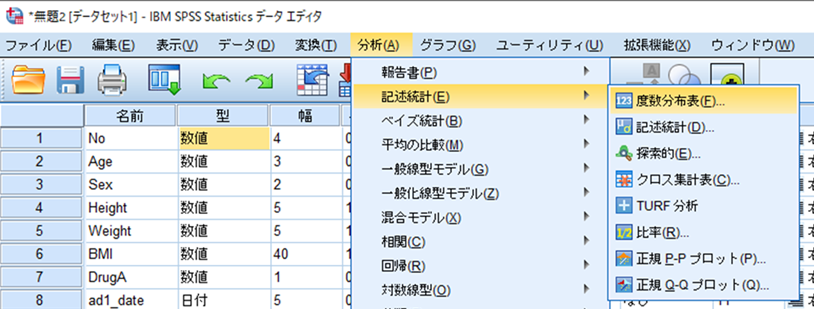
連続変数を選び、図2のようにチェックを入れておきます。選択できたら[OK]を押します。
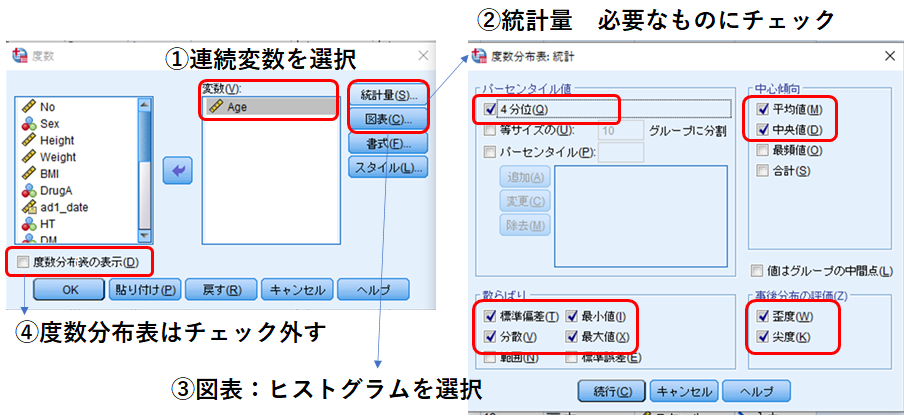
すると、結果が出力されます。
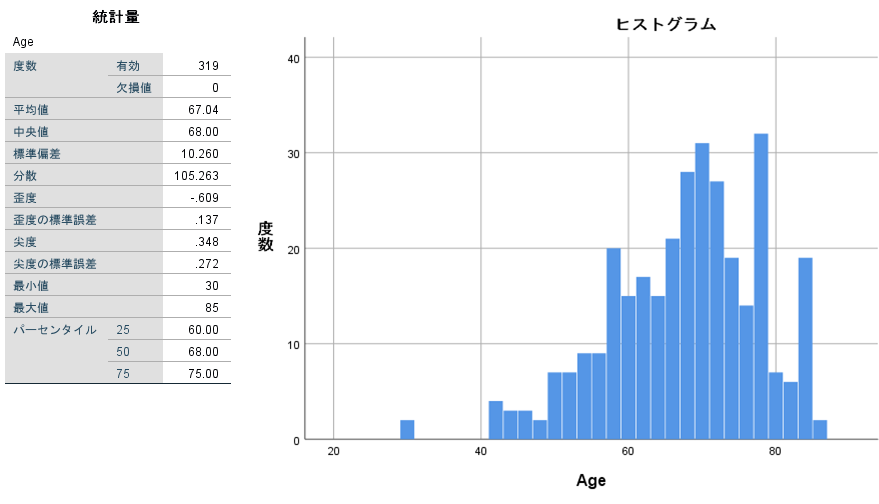
データがどのような分布をとっているかがわかると思います。チェックポイントは
①平均、標準偏差、中央値、パーセンタイル
②正規分布しているか?(SPSSでは尖度0、歪度0が基本)
正規分布についてはこちら>>正規分布 統計で一番大切な分布
③外れ値や誤入力はないか?
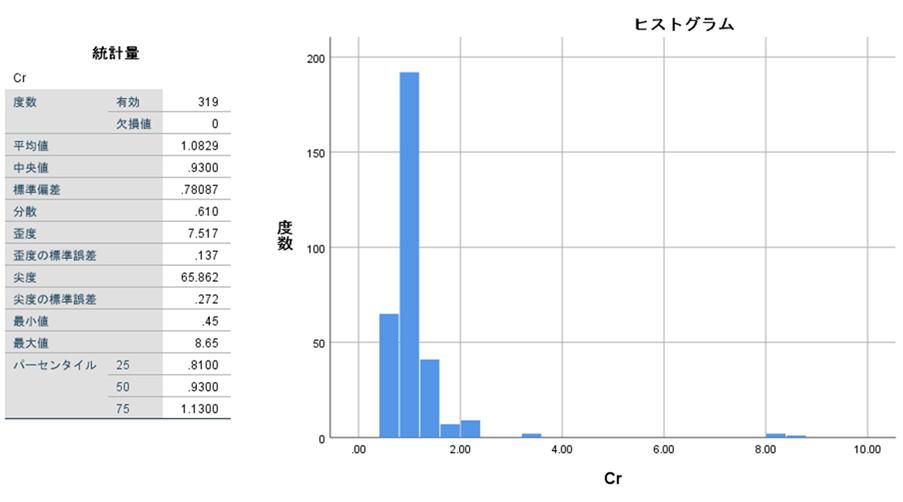
ヒストグラムをみると外れ値が一目瞭然です。外れ値や誤入力と思われる値(年齢150歳など、常識的にあり得ない値)はありませんか?外れ値はそれが本当の値であれば外してはいけません。誤入力はデータを見直して修正しましょう。検定のときに大きく影響してきます。
連続変数の記述統計②
別のやり方を紹介します。ヒストグラムを描くことはできませんが、一度に算出できます。
分析➡記述統計➡記述統計 必要な連続変数を選びます。一度に複数選ぶことができます。
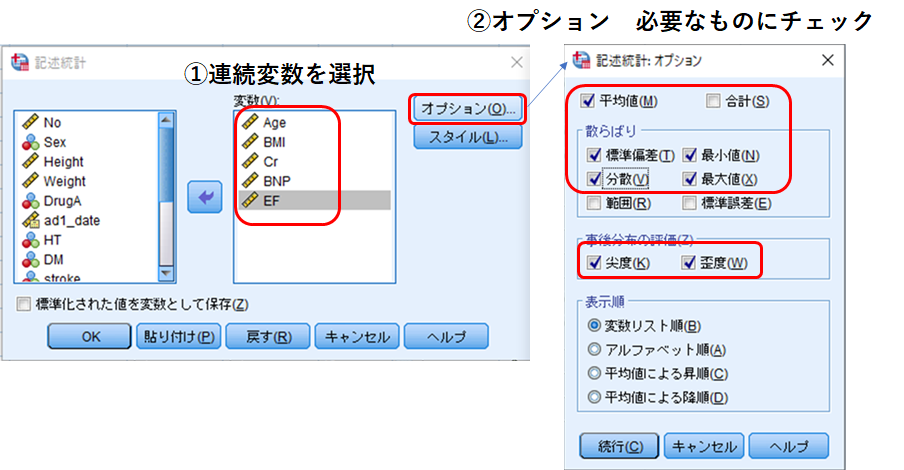
図5のように複数の変数が表で出力されます。
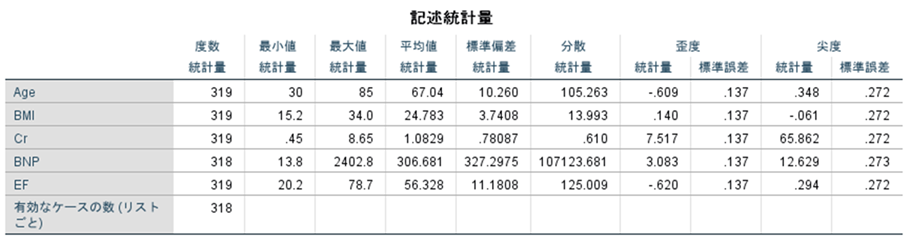
この[記述統計]ではパーセンタイルもヒストグラムも算出されません。そのため、正規分布しない場合や正規分布しているのかわからない場合は先ほどの[度数分布表]を使います。この表をみて標準偏差が大きい、歪度・尖度が0から大きく外れている場合は正規分布しないことが多いので、記述統計を使いましょう。また、平均値と最大値もしくは最大値が大きく外れている場合は外れ値を含んでいる可能性があるので、こちらも度数分布表でヒストグラムを書いて確認しましょう。
例えば、この表ではCrは平均と最大値が大きく乖離しており、尖度もとても大きくなっています。[度数分布表]を使って出力すると、このようになります。
決まり事として論文や学会で報告する場合は
正規分布に従う場合:平均±標準偏差 Age 67.0±10.3
正規分布に従わない場合:中央値(25パーセンタイル-75パーセンタイル) Cr 0.93 (0.81-1.13)
というように記載します。
名義変数の記述統計
名義変数の場合は度数分布表を使います。
分析➡記述統計➡度数分布表 (図1と同様)
連続変数とはチェックを入れる項目が違います。
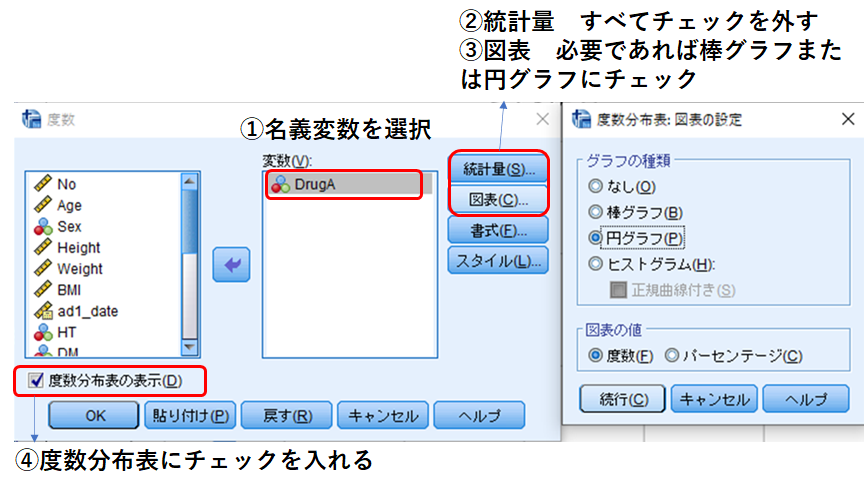
図7のとおりにチェックを入れて[OK]すると、出力されます。
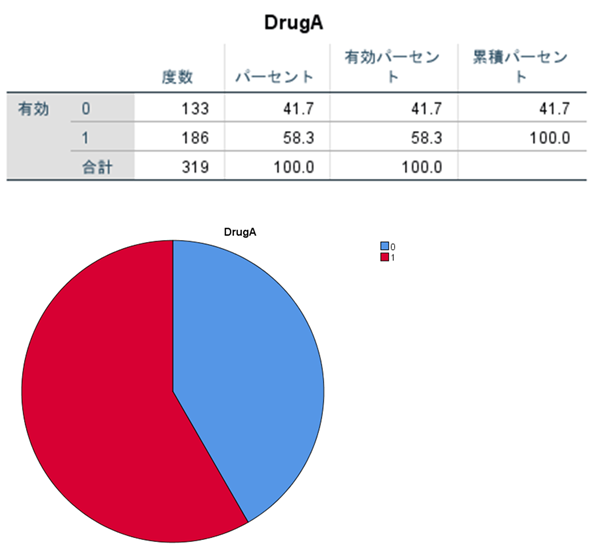
報告するときは 度数(%)で報告します。 DrugA 186 (58.3%)
欠損値がないか確認し、あれば埋めておきましょう。
これでPatient characteristicsにあたる部分が完成したのではないでしょうか?研究に参加した患者背景が分かったところで、検定を始めていきます。

コメント