
従属変数、独立変数が両方とも名義変数の場合、X2検定やFisherの正確検定を行います。X2検定は独立の検定とも呼ばれます。
X2(カイ二乗)検定
例では心不全入院患者さんのデータを用います。新薬Drug A使用の有無で心不全再入院率に違いがあるかを見ていきます。従属変数:再入院(ad2)、独立変数:Drug Aの使用(Drug A)としています。
記述統計➡クロス集計表
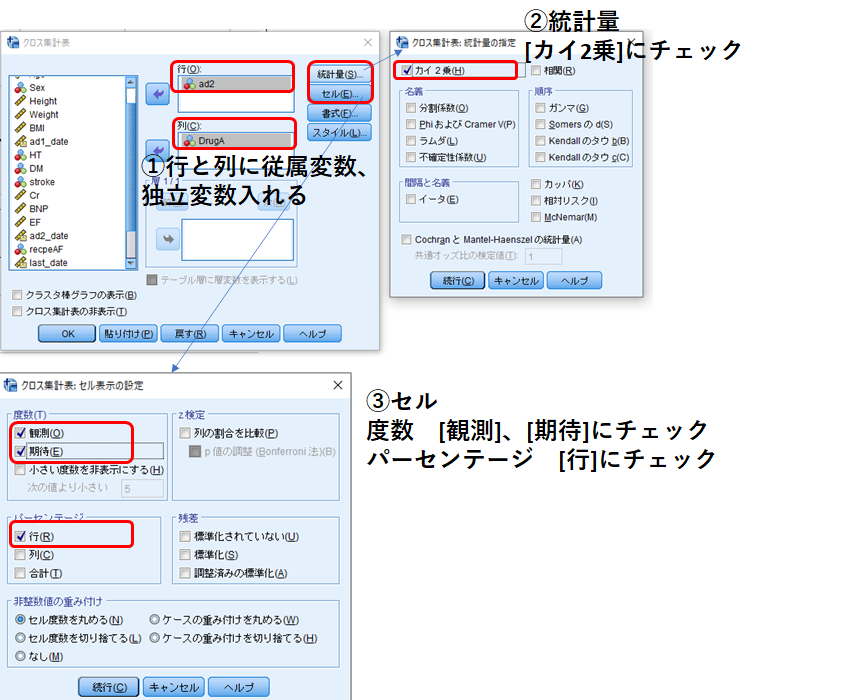
①行と列に従属変数、独立変数を入れます。行は横、列は縦です。逆でもOKです。
②統計量で[カイ2乗]にチェック。
③セルで[観測]、[期待]にチェック。パーセンテージは従属変数を入れたほうにすると見やすいです。ここでは行ですが、両方のパーセンテージを算出したければ、両方にチェックをつけてもよいです。[続行]をクリックすると図3のように出力されます。
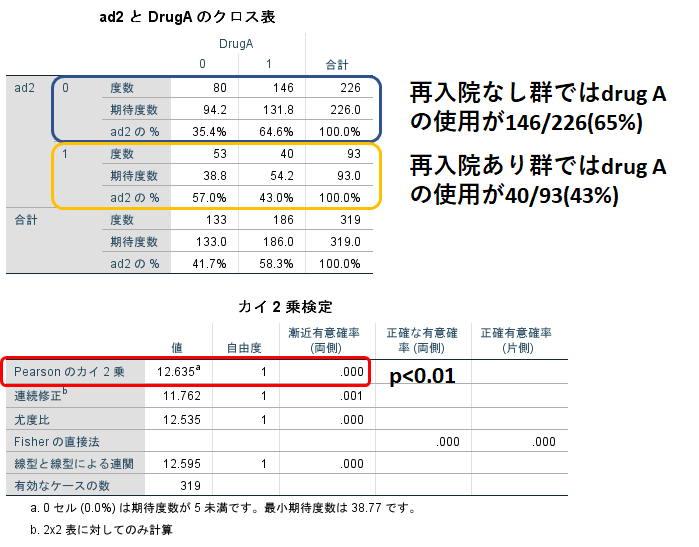
クロス表とX2検定の結果が出力されます。
従属変数は行(横)なので、横に見ていきます。従属変数を列(縦)にした場合は縦に見ます。
この場合は再入院なし群ではdrug Aの使用が146/22(65%)、再入院あり群では40/93 (43%)でした。再入院なし群でdrug Aの使用率が高いという結果ですが、これは有意な差なのでしょうか?
ここでX2検定の結果をみてみると、p<0.01となっており、この差は有意な差であると言えます。結果を報告する場合はこのように記載します。
| 再入院なし n=226 | 再入院あり n=93 | p値 | |
| Drug A (%) | 146 (65) | 40 (43) | <0.01 |
度数(パーセンテージ)、群全体の度数を示すnは小文字を使用します。標本全体を占めす場合は大文字です。p値はいろいろな書き方を見かけますが、0.01未満の場合は具体的な値は書かずに、<0.01と書くことが多いです。
Fisherの正確検定
図3のX2検定の表を見てみると[Fisherの直接法]というものも同時に出力されています。つまり、同じやり方でFisherの正確検定もできます。
別の例を挙げてみます。従属変数:再入院(ad2)、独立変数:脳梗塞の既往(stroke)として結果を出力すると図5のようになりました。
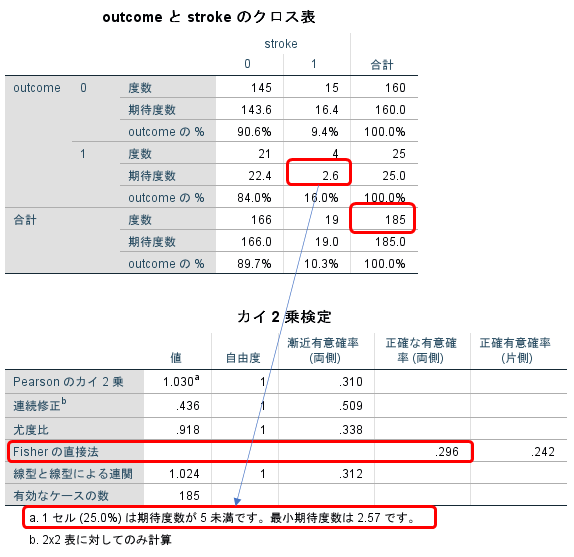
通常、全サンプル数が20未満(ここでは185)、少なくとも1つのセルの期待度数が5未満(ここでは1つのセルにおいて期待度数2.6)の場合にはFisherの直接法を使います。
この場合は1つのセルの期待値が5未満であるので、Fisherの直接法を使用します。両側検定と片側検定が算出されますが、基本的には両側検定を採用します。


コメント